Thu, 03 Mar 2016
House organizing recently
This week I've been doing some house organizing. Specifically:
- I bought and installed a new shower caddy.
- I bought and installed some under-sink shelving in the kitchen and each of the two bathrooms.
- I bought and installed new shower rings.
- With a housemate, I added some new shelves within our kitchen shelves, increasing organization and hypothetically doubling the storage space.
- I bought and installed a sponge holder, which included cleaning the side of the sink.
- I bought and installed a crazy-awesome-designed sink strainer. Credit to Greg, I think, for remarking on this product looking smartly-designed. It is.
That's today's life note.
[/organize] permanent link and comments
Fri, 04 Dec 2015
How this website gets published
In case you're interested, here are the technical details on how this website gets published.
- On my laptop, there's a directory, ~/projects/asheesh.org.
- It contains a git clone of a private git repository. That private git repository is hosted on my personal server, rose.makesad.us.
- I run a git hosting app called Gogs, using a web app package manager called Sandstorm, on my server which runs Debian GNU/Linux.
- Inside ~/projects/asheesh.org there is a directory called entries. Inside that, you'll find entries/note.
- I create a file called entries/note/software/this-site.mw which contains the content of this blog post, in MediaWiki markup format, because when I first put this publishing system together, I was hopeful that MediaWiki markup format would win against Markdown. (I lost that battle.)
- I commit that file to git.
- I run make update-snapshot on my laptop, which uses Pyblosxom (a 2004-era static site publishing system that I'm happy to say is still being maintained) to convert the various Markdown files and template files into HTML. Pyblosxom uses the file's mtime on disk to generate the datestamp that you see, so I use a tool called git-set-mtime to automatically use the last git commit time as the file's mtime on disk.
- I run make deploy which uses the owncloudcmd program to push the static site content to a directory on rose.makesad.us. Specifically, it synchronizes to an instance of another app in my Sandstorm setup called Davros.
- Davros is shockingly convenient, because it contains the ability to receive files via owncloudcmd _and_ it has the ability to serve them out to the world. For this, it relies on the help of Sandstorm and Sandstorm's static publishing API.
- So when a request comes in, it hits nginx running in the Debian-ish world on my server, and nginx knows that for the asheesh.org host, to send the request to the Sandstorm service running on localhost:6080. Sandstorm then looks at the inbound request, notices it's for asheesh.org, and does a DNS lookup check to find out which _grain_ (the Sandstorm term for app instance) is responsible for serving static content for asheesh.org, finds the Davros grain, and then serves the HTML that Davros registerd with Sandstorm via the static publishing API.
- Savvy systems-minded people will appreciate that the Davros code isn't on the critical path for serving a web page.
That's a large collection of things, but I like how they fit together. And, moreover, the fact that you can see this content means that the whole pipeline is working!
[/software] permanent link and comments
Sun, 22 Jun 2014
Interactive semi-automated package review (by abusing Travis-CI)
I just did some Debian package review in a somewhat unusual way, and I wanted to share that. I'm hoping other Debian developers (and other free software contributors) that need to review others' contributions can learn something from this, and that I can use this blog post as a way to find out if other people are doing something similar.
It was pretty exciting! At the end of it, I joined #debian-mentors to talk about how my cool process. Someone summarized it very accurately:
<sney> it almost sounds like you're working to replace yourself with automation
Context about alpine in Debian
(Skip to "Package review, with automation" if you're familiar with Debian.)
I'm the maintainer of alpine in Debian. There are quite a few problems with the alpine package in Debian right now, the biggest of which are:
- We're one version behind -- 2.11 is the latest available, but 2.10 is the newest that we have in Debian.
- The packaging uses a decreasingly-popular packaging helper, cdbs, about which I happen to know less than the dh-style helper (aka dh7).
- There are lots of bugs filed, and I don't respond in a timely fashion.
This doesn't change my deep love for alpine -- I've had that for about half my life now, and so far, I don't see it going away.
A month or so ago, I got a friendly private message from Unit193, saying he had converted the package to the dh style, and also packaged the newer version. They wanted to know if they should clean this up into something high-enough quality to land in Debian.
(In Debian, we have a common situation where enthusiastic users update or create a new package, and aren't yet Debian Developers, so they don't have permission to upload that directly to the "Debian archive", which is the Debian equivalent of git master. Package "sponsorship" is how we handle that -- a Debian Developer reviews the package, makes sure it is of high quality, and uploads it to the Debian archive along with the Debian Developer's OpenPGP signature, so the archive processing tools know to trust it.)
On Friday evening, I had a spare moment, so I sent a private message to Unit193 apologizing for not getting back to them in a reasonable amount of time. Having another person help maintain is a pretty exciting prospect, and I wanted to treat that enthusiasm with the respect it deserves, or at least apologize when I haven't. I was surprised to see a reply within a few minutes. At that point, I thought: I wasn't planning on doing any package review this weekend, but if they're online and I'm online... might as well!
Package review, with automation
Unit193 and I popped into ##alpine on irc.freenode.net, and I started reading through their packaging changes, asking questions. As I asked questions, I wondered -- how will I know if they are going to fix the issues I'm raising?
Luckily, Unit193 wanted to use git to track the packaging, and we settled on using git-buildpackage, a tool that was fairly new to both of us. I thought, I might as well have some executable documentation so I don't forget how to use it. ("Executable documentation" is Asheesh-speak for a shell script.)
One thing I knew was that I'd have to test the package in a pbuilder, or other pristine build environment. But all I had on me at the moment was my work laptop, which didn't have one set up. Then I had a bright idea: I could use Travis-CI, a public continuous integration service, to check Unit193's packaging. If I had any concerns, I could add them to the shell script and then point at the build log and say, "This needs to be fixed." Then there would be great clarity about the problems.
Some wonderful things about Travis-CI:
- They give you root access on an Ubuntu Precise (10.04) virtual machine.
- Their build hosts are well-connected to the Internet, which means fast downloads in e.g. pbuilder.
- They will let you run a build for up to 50 minutes, for free.
- Build just means "command" or "set of commands," so you can just write a shell script and they will run it.
- Travis-CI will watch a github.com repository, if you like. This means you can 'git commit --allow-empty' then 'git push' and ask it to re-run your script.
Since Unit193's packaging was in git (but not on github), I created a git repo containing the same contents, where I would experiment with fixes for packaging problems I found. It'd be up to Unit193 to fix the problems in the Alioth packaging. This way, I would be providing advice, and Unit193 would have an opportunity to ask questions, so it would be more like mentorship and less like me fixing things.
We did a few rounds of feedback this way, and got the packaging to higher and higher quality. Every time Unit193 made a fix and pushed it, I would re-run the auto-build, and see if the problems I spotted had gone away.
While the auto-build runs, I can focus on conversing with my mentee about problems or just generally chatting. Chatting is valuable community-building! It's extremely nice that I can do that while waiting on the build, knowing that I don't have to read it carefully -- I can just wait a few minutes, then see if it's done, and see if it's red or green. Having the mentee around while I'm reviewing it means that I can use the time I'm waiting on builds as fun free software social time. (Contrast this with asynchronous review, where, all alone, I would wait for a build to finish, then write up an email at the end of it all.)
This kind of mentorship + chatting was spread out over Friday night, Saturday night, and Sunday morning. By the end of it, we had a superb package that I'm excited to sign and push into Debian when I'm next near my OpenPGP key.
Implementation details
You can see the final shell script here:
And you can see the various builds here:
The shell script:
- Alternates between the Alioth packaging vs. my fork of it. (This way, I can test packaging changes/suggestions.)
- Disables ccache in pbuilder, due to a permissions problem with ccache/pbuilder/travis-ci, and I didn't need ccache anyway.
- Handles 'git dch' slightly wrong. I need to figure that out.
- Optionally passes --git-ignore-new to git-buildpackage, which was required initially, but should not be required by the time the package is ready. (This is an example of a thing I might forget to remark upon to my mentee.)
- Plays games with git branches so that git-buildpackage on Travis-CI can find the pristine-tar branch.
- Tries to use cdn.debian.net as its mirror, but on Saturday ran into problems with whicever mirror that is, so it falls back to mirror.mit.edu in case that fails.
- Contains a GPG homedir, and imports the Debian archive key, so that it can get past Ubuntu-Debian pbuilder trust issues.
I also had a local shell script that would run, effectively:
- git commit --allow-empty -m 'Trigger build'
- git push
This was needed since I was basically using Travis-CI as remote shell service -- moreover, the scripts Travis-CI runs are in a different repo (travis-debcheck) than the software I'm actually testing (collab-maint/alpine.git).
Unit193 and I had a technical disagreement at one point, and I realized that rather than discuss it, I could just ask Travis-CI to test which one of us was right. At one point in the revisions, the binary package build failed to build on Precise Pangolin (the Ubuntu release that the Travis-CI worker is running), and Unit193 said that it was probably due to a problem with building on Ubuntu. So I added a configuration option to build just the source package in Ubuntu, keeping the binary package test-build within the Debian sid pbuilder, although I believed that there was actually a problem with the packaging. This way, I could modify the script so that I could demonstrate the problem could be reproduced in a sid pbuilder. Of course, by the time I got that far, Unit193 had figured out that it was indeed a packaging bug.
I also created an option to SKIP_PBUILDER; initially, I wanted to get quick automated feedback on the quality of the source package without waiting for pbuilder to create the chroot and for the test build to happen.
You might notice that the script is not very secure -- Niels Thykier already did! That's fine by me; it's only Travis-CI's machines that could be worsened by that insecurity, and really, they already gave me a root shell with no password. (This might sound dismissive of Travis-CI -- I don't mean it to be! I just mean that their security model already presumably involves throwing away the environment in which my code is executing, and I enjoy taking advantage of that.)
Since the Travis virtual machine is Ubuntu, and we want to run the latest version of lintian (a Debian packaging "lint" checker), we run lintian within the Debian sid pbuilder. To do that, I use the glorious "B90lintian" sample pbuilder hook script, which comes bundled with pbuilder in /usr/share/doc/pbuilder/.
The full build, which includes creating a sid pbuilder from scratch, takes merely 7-10 minutes. I personally find this kind of shockingly speedy -- in 2005, when I first got involved, doing a pbuilder build seemed like it would take forever. Now, a random free shell service on the Internet will create a pbuilder, and do a test build within it, in about 5 minutes.
Package review, without automation
I've done package review for other mentees in the past. I tend to do it in a very bursty fashion -- one weekend day or one weeknight I decide sure, it's a good day to read Debian packages and provide feedback.
Usually we do it asynchronously on the following protocol:
- I dig up an email from someone who needed review.
- I read through the packaging files, doing a variety of checks as they occur to me.
- If I find problems, I write an email about them to the mentee. If not, success! I sign and upload the package.
There are some problems with the above:
- The burstiness means that if someone fixes the issues, I might not have time to re-review for another month or longer.
- The absence of an exhaustive list of things to look for means that I could fail to provide that feedback in the first round of review, leading to a longer wait time.
- The person receiving the email might not understand my comments, which could interact really badly with the burstiness.
I did this for Simon Fondrie-Teitler's python-pypump package recently. We followed the above protocol. I wrote a long email to Simon, where I remarked on various good and bad points of the packaging. It was part commentary, part terminal transcript -- I use the terminal transcripts to explain what I mean. This is part of the email I sent:
I got an error in the man page generation phase -- because at
build-time, I don't have requests-oauthlib:
make[2]: Leaving directory `/tmp/python-pypump-0.5-1+dfsg/docs'
help2man --no-info \
-n 'sets up an environment and oauth tokens and allows for interactive testing' \
--version-string=0.5.1 /tmp/python-pypump-0.5-1+dfsg/pypump-shell > /tmp/python-pypump-0.5-1+dfsg/debian/pypump-shell.1
help2man: can't get `--help' info from /tmp/python-pypump-0.5-1+dfsg/pypump-shell
Try `--no-discard-stderr' if option outputs to stderr
make[1]: *** [override_dh_auto_build] Error 1
This seems to be because:
➜ python-pypump-0.5-1+dfsg ./pypump-shell
Traceback (most recent call last):
File "./pypump-shell", line 26, in <module>
from pypump import PyPump, Client
File "/tmp/python-pypump-0.5-1+dfsg/pypump/__init__.py", line 19, in <module>
from pypump.pypump import PyPump, WebPump
File "/tmp/python-pypump-0.5-1+dfsg/pypump/pypump.py", line 28, in <module>
from six.moves.urllib import parse
ImportError: No module named urllib
$ ./pypump-shell
Traceback (most recent call last):
File "./pypump-shell", line 26, in <module>
from pypump import PyPump, Client
File "/tmp/python-pypump-0.5-1+dfsg/pypump/__init__.py", line 19, in <module>
from pypump.pypump import PyPump, WebPump
File "/tmp/python-pypump-0.5-1+dfsg/pypump/pypump.py", line 29, in <module>
from requests_oauthlib import OAuth1
ImportError: No module named requests_oauthlib
The deeper problem was a missing build-dependency, and I explained that in my email. But the meta problem is that Simon didn't try building this in a pbuilder, or otherwise clean build environment.
Simon fixed these problems, and submitted a fresh package to Paul Tagliamonte and myself. It happened to have some typos in the names of the new build dependencies. Paul reviewed the fixed package, noticed the typos, fixed them, and uploaded it. Simon had forgotten to do a test build the second time, too, which is an understandable human failure. There was a two-day delay between Simon's fixed resubmission, and Paul signing+uploading the fixed result.
In a pedagogical sense, there's something disappointing about that exchange for me: Paul fixed an error Simon introduced, so we're not teaching Simon to take total responsibility for his packages in Debian, nor to understand the Debian system as well as he could. (Luckily, I think Simon already understands the importance of taking responsibility! In this case, it's just a hypothetical in this case.)
For the future
The next time I review a package, I'm going to try to do something similar to my Travis-CI hack. It would be nice to have the do.sh script be a little more abstract; I imagine that as I try to use it for a different package, I'll discover the right abstractions.
I'd love it if Travis-CI did not require the git repositories to be on GitHub. I'd also like if the .travis.yml file could be in a different path. If so, we could create debian/travis-configuration (or something) and keep the packaging files nice and separate from the upstream source.
I'd also love to hear about other people's feedback. Are you doing something similar? Do you want to be? Would you have done some of this differently? Leave a comment here, or ping me (paulproteus) on #debian-mentors on irc.debian.org (aka irc.oftc.net).
I'll leave you with some conversation from #debian-mentors:
<paulproteus> The automation here, I think, is really interesting. <paulproteus> What I really want is for mentees to show up to me and say "Here is my package + build log with pbuilder, can you sponsor it please?" <Unit193> Oooooh! -*- Unit193 gets ideas. <paulproteus> Although the irony is that I actually like the community-building and relationship-building nature of having these things be conversations. <bremner> how will this brave new world cope with licensing issues? <paulproteus> bremner: It's not a replacement for actual review, just a tool-assist. <paulproteus> bremner: You might be relieved to know that much of Unit193's and my back and forth related to get-orig-source and licensing. (-: <bremner> I didn't doubt you ;). <paulproteus> If necessary I can just be a highly productive reviewer, but I would prefer to figure out some way that I can get other non-paulproteus people to get a similar assist. <paulproteus> I think the current blocker is "omg travis why are you bound to githubbbbbbbb" which is a reasonable concern.
[/debian] permanent link and comments
Sun, 27 Apr 2014
Personal backups
My main computers nowadays are:
- My personal laptop.
- My work laptop.
- My phone.
Given that, and given my propensity to start large fun home networking related projects but then leave them unfinished, here is my strategy for having reliable backups of my personal laptop:
- Buy an external hard disk, preferably the kind that requires no external power supply.
- Store it at work, and make an encrypted filesystem on it.
- Once per two weeks, take my personal laptop to work, where I will connect the external disk over USB, and do backups to it using e.g. dirvish (which is something like Apple's Time Machine software).
- When the backup finishes, use a post-it note to write today's date on the external disk, then put it back in my work filing box.
This seems to have the following advantages:
- No decrease in privacy -- the data is stored encrypted.
- Convenient off-site storage.
- I don't have to be thoughtful about what I am backing up.
- Since I'll be using dirvish, restoring data will be easy.
If people have any thoughts about this, or do things a different way and have pros or cons to share, I'd love to hear.
I realize this doesn't protect my phone or work laptop. I'll work on those some other time.
[/sysop] permanent link and comments
Fri, 28 Feb 2014
Schedule something with me
If you want to set up an evening hang out with me, or anything else where you'd like to meet up, here's the best strategy if you use Google Calendar:
- Create an event on your calendar with the time and date. In the name of the event, summarize it (for example: "Alice and Asheesh catch up re: fundraising" or "Bob and Asheesh hang out at El Rio bar").
- "Edit" the event, and add asheesh@asheesh.org as a person to invite.
- Click "Save" and send me an invitation.
To do an amazing job, here are some extra rules:
- Always give me 24 hours or more lead-time.
- Give me two options, one labeled "(backup)" -- for example. "Bob and Asheesh hang out at El Rio bar" and "Bob and Asheesh hang out at El Rio bar (backup)".
- Then I'll click confirm on one of them, and I will click "No" on the other one. And that'll be that!
If you're too impatient for that (which is fine)
- Submit two proposed times
- Wait for me to eamil you saying yes (I'll also GCal invite you back)
Rationale
This may seem bizarrely bureaucratic and impersonal, but since I often drop the ball on scheduling social or professional catch-up time, I wanted to create a system where successful results are easily achieved. In return for dealing with this automated interaction, you'll get a happy, relaxed, attentive Asheesh.
[/communication] permanent link and comments
Tue, 28 Jan 2014
What happens in my inbox
At this moment, I'm so impressed by what happens in my inbox. I see quotes like these, all referring to events or resources made as part of Open Source Comes to Campus.
- "I had a student stop by the office today and tell me that Saturday's event was a real game changer for him."
- Conversations with freegeekchicago.org.
- "I worked through the student GIT setup <https://openhatch.org/wiki/Open_Source_Comes_to_Campus/Practicing_Git/Students>. It looks good."
- Other people than me are staying in touch with computer science departments to show them that our event pages do in fact thank them.
- "Please be sure to emphasize that OpenHatch has a focus on being newcomer-friendly and gender-diverse," says someone who is a new volunteer (we met them in October).
- " I just wanted to say thank you so much for taking the time to walk us through the [git] tutorial. My classmate and I were attending our first open source event ever in our lives, and we were a bit intimidated at the beginning. It was great to meet your team and to have some fun in a group setting."
I ran into these because I was searching for OpenHatch-related mails to reply to. I figured I should archive/delete the ones that are already taken care-of. So the mail mostly isn't directed at me; instead, it's just stuff in OpenHatch-land generally.
I seem to have worked on something that is at least moderately successful, and at least moderately well-organized. That is pretty seriously heartening.
[/me] permanent link and comments
Thu, 26 Dec 2013
New job (what running Debian means to me)
Five weeks ago, I started a new job (Security Engineer, Eventbrite). I accepted the offer on a Friday evening at about 5:30 PM. That evening, my new boss and I traded emails to help me figure out what kind of computer I'd like. Time was of the essence because my start date was very next day, Tuesday.
I wrote about how I value pixel count, and then RAM, and then a speedy disk, and then a speedy CPU. I named a few ThinkPad models that could be good, and with advice from the inimitable danjared, I pointed out that some Dell laptops come pre-installed with Ubuntu (which I could easily swap out for Debian).
On Monday, my boss replied. Given the options that the IT department supports, he picked out the best one by my metrics: a MacBook Pro. The IT department would set up the company-mandated full-disk encryption and anti-virus scanning. If I wanted to run Linux, I could set up BootCamp or a virtualization solution.
As I read the email, my heart nearly stopped. I just couldn't see myself using a Mac.
I thought about it. Does it really matter to me enough to call up my boss and undo an IT request that is already in the works, backpedaling on what I claimed was important to me, opting for brand anti-loyalty to Apple over hardware speed?
Yes, I thought to myself. I am willing to just not work there if I have to use a Mac.
So I called $BOSS, and I asked, "What can we do to not get me a Mac?" It all worked out fine; I use a ThinkPad X1 Carbon running Debian for work now, and it absolutely does everything I need. It does have a slower CPU, fewer pixels, and less RAM, and I am the only person in the San Francisco engineering office not running Mac OS. But it all works.
In the process, I thought it made sense to write up some text to $BOSS. Here is how it goes.
Hi $BOSS,
Thanks for hearing my concerns about having a Mac. It would basically be a fairly serious blow to my self image. It's possible I could rationalize it, but it would take a long time, and I'm not sure it would work.
I don't at all need to start work using the computer I'm going to be using for the weeks afterward. I'm OK with using something temporarily that is whatever is available, Mac or non-Mac; I could happily borrow something out of the equipment closet in the short term if there are plans in the works to replace it with something else that makes me productive in the long term.
For full-disk encryption, there are great solutions for this on Linux.
For anti-virus, it seems Symantec AV is available for Linux <http://www.symantec.com/business/support/index?page=content&id=HOWTO17995>.
It sounds like Apple and possibly Lenovo are the only brands that are available through the IT department, but it is worth mentioning that Dell sells perfectly great laptops with Linux pre-installed, such as the XPS 13. I would perfectly happily use that.
If getting me more RAM is the priority, and the T440s is a bad fit for $COMPANY, then the Lenovo X230 would be a great option, and is noticeably less expensive, and it fits 16GB of RAM.
BootCamp and the like are theoretical possibilities on Macs, but one worry I have is that if there were a configuration issue, it might not be worth me spending work time to have me fix my environment, but instead I would be encouraged for efficiency to use Mac OS, which is well-tested on Apple hardware, and then I would basically hate using my computer, which is a strong emotion, but basically how I would feel.
Another issue (less technical) is that if I took my work machine to the kinds of conferences that I go to, like Debconf, I would find myself in the extremely uncomfortable position of advertising for Apple. I am pretty strongly unexcited about doing that.
Relating to the self-image issue is that it means a lot to me to sort of carry the open source community with me as I do my technical work, even if that technical work is not making more open source software. Feeling part of this world that shares software, and Debian in particular where I have a strong feeling of attachment to the community, even while doing something different, is part of what makes using computers fun for me. So it clashes with that to use Mac OS on my main machine, or to feel like I'm externally indistinguishable from people who don't care about this sort of community.
I am unenthusiastic about making your life harder and looking like a prima donna with my possibly obscure requirements.
I am, however, excited to contribute to $COMPANY!
I hope that helps! Probably nothing you couldn't have guessed in here, but I thought it was worth spelling some of that out. Happy to talk more.
-- Asheesh.
[/debian] permanent link and comments
Sat, 02 Nov 2013
Censored on Facebook
For the first time in what feels like years, I wanted to share something with my friends on Facebook.
The background was that I read a note on Slashdot that Linus Torvalds thought a presidential candidate's remarks on a topic related to airline security were "moron"ic. So I did my own research, and I disagreed. I figured this was a topic of general enough interest that all my Facebook friends might be interested in knowing my position, so I wanted to share that.
Facebook didn't let me.
I tried first with a link to snopes.com, which blocked me with the rationale that http://snopes.com/images/template/snopes.gif is "spammy or unsafe":
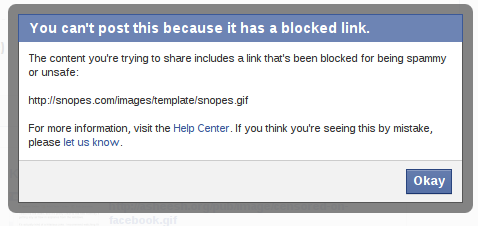
Then I thought I'd be clever, and I linked to the .nyud.net version of the snopes page on the topic. I earned the same message that my post included a blocked link.
So then I tried again, with a link to a video on YouTube of the same clip.
That's when I first got the extremely generic message that "The message could not be posted to this Wall." You can see the animation of what happened next by hovering below.
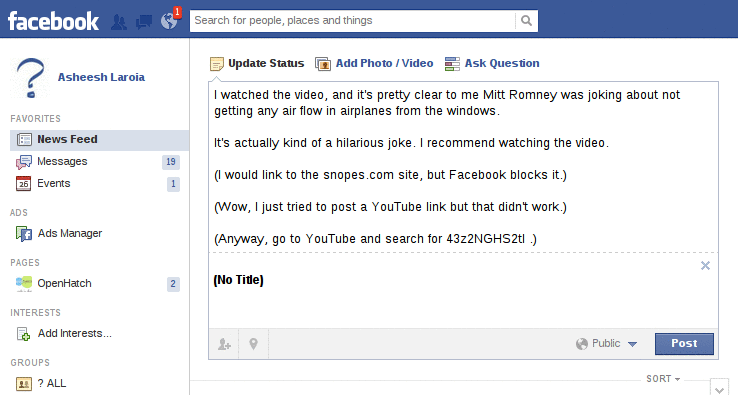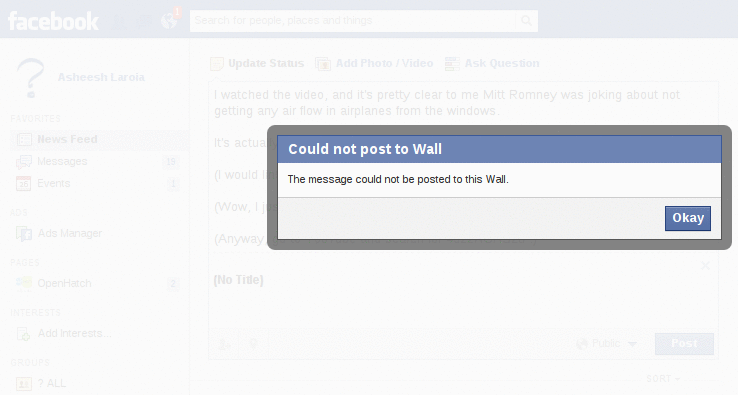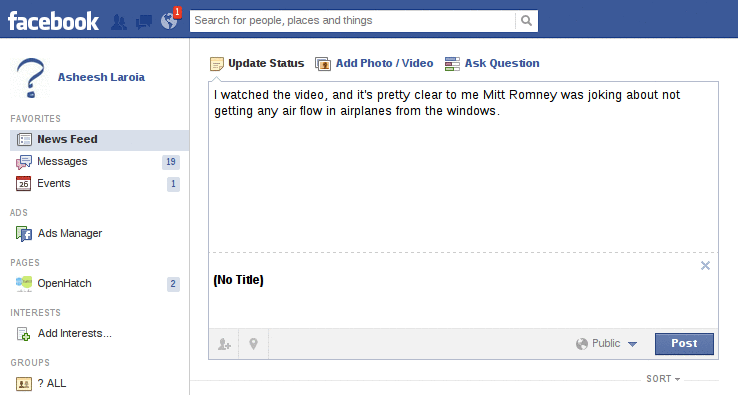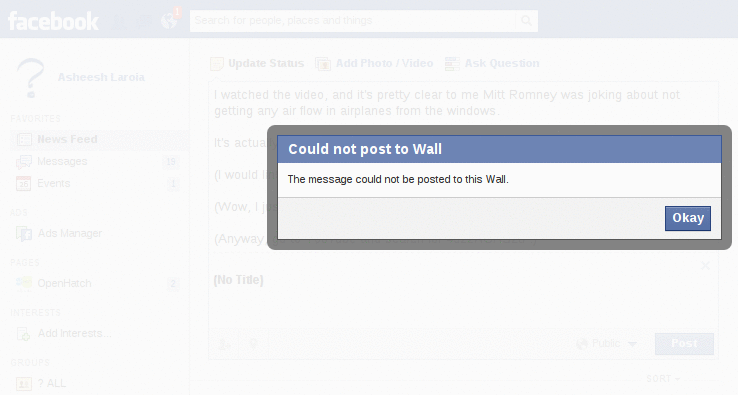
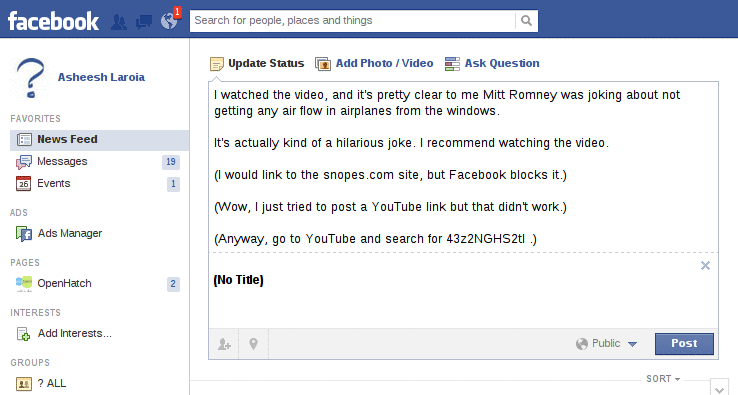
Finally, I removed all the links, and kept the first bit of text. For this, I got the same generic error: "The message could not be posted to this Wall."
Update: Patrick points out I should link to the actual video. Here it is, embedded:
(BTW: The first thing I did was to click "let us know" to indicate that I think I'm seeing this by mistake. I filled out the form to indicate there was a problem in an honest, respectful way. I got back an email autoresponse that said, "Thanks for taking the time to submit this report. While we don't currently provide individual support for this issue, this information will help us identify bugs on our site.")
[/software] permanent link and comments
Fri, 18 Oct 2013
On Humility
Today I'd like to quote a passage from one of my favorite books, Open Advice, edited by the astounding Lydia Pintscher.
I'd like to quote it because someone helped me with a technical problem today, and today was definitely a day when I needed it.
This passage is written by Rich Bowen.
Humility
I had been doing technical support, particularly on mailing lists, for about two years, when I first started attending technical conferences. Those first few years were a lot of fun. Idiots would come onto a mailing list, and ask a stupid question that a thousand other losers had asked before them. If they had taken even two minutes to just look, they would have found all the places the question had been answered before. But they were too lazy and dumb to do that.
Then I attended a conference, and discovered a few things.
First, I discovered that the people asking these questions were people. They were not merely a block of monospaced black text on a white background. They were individuals. They had kids. They had hobbies. They knew so much more than I did about a whole range of things. I met brilliant people for whom technology was a tool to accomplish something non-technical. They wanted to share their recipes with other chefs. They wanted to help children in west Africa learn how to read. They were passionate about wine, and wanted to learn more. They were, in short, smarter than I am, and my arrogance was the only thing between them and further success.
When I returned from that first conference, I saw the users mailing list in an entirely different light. These were no longer idiots asking stupid questions. These were people who needed just a little bit of my help so that they could get a task done, but, for the most part, their passions were not technology. Technology was just a tool. So if they did not spend hours reading last year’s mailing list archives, and chose instead to ask the question afresh, that was understandable.
And, surely, if on any given day it is irritating to have to help them, the polite thing to do is to step back and let someone else handle the question, rather than telling them what an imbecile they are. And, too, to remember all of the times I have had to ask the stupid questions.
[/people] permanent link and comments
Sun, 28 Jul 2013
Recommendations on setting up wifi repeaters
My old housemate Will emailed me saying he wanted to get a second wifi router to use as a repeater. I realized that I haven't written my standard recommendation down ever, just repeatedly used it to great success. So, here it is:
My general recommendation here is to build your own "wifi repeater" out of two "wifi routers", rather than buying something that calls itself a repeater. It relies on Ethernet bridging rather than any advanced wifi technology, which in my opinion makes it easy to diagnose.
+---------------------------------------------------------------------+
| Main wifi router |
| uplink port 1 port 2 port 3 port 4 |
+-+-----+-----------------+------+--+---------+--+-------+---+------+-+
| | | | | | | | | |
+-----+ +---+--+ +---------+ +-------+ +------+
| |
| |
| |
V |
+-----------+ |
| cable | |
| modem or | |
| whatever | |
+-----------+ V
+----------------+ +------------------------+
| | a/c power | |
| ethernet over +------------------->| ethernet over |
| powerline | | powerline |
+----------------+ +----------+-------------+
|
|
DO NOT USE!!! +------+ V
+--------------------->| | +-------+ +---------+ +----------+ +--------+
|uplink| |port 1 | | port 2 | |port 3 | | port 4 |
+------+------------+-------+---+---------+--+----------+--+--------+
| second wifi router (DISABLE DHCP on internal network on 2nd rtr)
+----------------------------------------------------------+--------+
If you don't want to do ethernet over powerline between them, you can do regular old Ethernet.
Crucially, you must disable DHCP for the second wifi router. Then anyone on the second network will have their DHCP broadcasts answered by the first wifi router.
Also you should manually set the admin IP on the second router to something like 192.168.1.2 if the main network uses 192.168.1.1 as the admin IP address.
Do not connect the second network's uplink port to anything.
It doesn't really matter if you set the ESSID (network name) of both networks to be the same or different. I would gently recommend setting them to be the same, and have the same key, so people's laptops can happily roam between them.
Note also that if you need wired network connectivity for computers near "2nd router", any computers you plug into the "port 1-4" ports will work fine. And the choice of port 1 on "Main wifi router" and "port 3" for "second wifi router" as the connection points is totally arbitrary.
Happy wifi-ing!
